How AI Is Transforming Recruitment
Discover how AI is transforming hiring—its impacts, benefits, and challenges. Is the future of interviews here? Find out now.
Written by
VidCruiter Editorial TeamReviewed by
VidCruiter Editorial TeamLast Modified
Jul 17, 2026
SHARE THIS ARTICLE
Bias is universal and measurable. It is a predictable system flaw, not a character defect in a few interviewers.
Unconscious bias is the bigger problem. It operates quietly and resists good intentions.
Structure beats willpower. Standardized questions and scoring are the single highest-leverage fix.
Training alone has mixed evidence. Awareness fades without process change behind it.
AI cuts both ways. It can support fair hiring or scale discrimination, depending on design and oversight.
Adverse impact creates legal risk regardless of intent. Outcomes are what regulators measure.
Hiring bias is the unfair preference or prejudice that shapes hiring decisions based on factors unrelated to the job. It leads teams to favor or overlook candidates for reasons that have nothing to do with competence.
Bias is common and well documented in recruitment, according to Harvard Business Review. It clouds judgment in ways most interviewers never notice. There are two broad categories.
Conscious bias is explicit preference an interviewer can recognize and may even state. A hiring manager who openly prefers one gender for a role is acting on conscious bias. These biases are easier to identify and address.
Unconscious bias operates below awareness. It surfaces when people "trust their gut" and lean on stereotypes instead of evidence. A common example is favoring a candidate who resembles a younger version of the interviewer. Because these patterns are deeply ingrained, they are harder to catch.
Bias does not wait for the final decision. It enters at every stage: how jobs are sourced, which resumes get screened in, how interviews are scored, and who receives the offer. A name on a resume can trigger assumptions before a candidate ever speaks.
The business case for addressing it is concrete. Unchecked bias raises legal exposure, weakens quality of hire, increases turnover, and narrows the talent you can reach. It also undermines diversity, equity, and inclusion (DEI) goals, which depend on fair evaluation to work at all.

Most hiring biases are human and fall into three groups: identity-based, interpersonal, and cognitive. Systemic bias from technology gets its own section below. Learning to name each one is the first step toward designing it out of your process.
Gender bias is preference or prejudice toward one gender over another during evaluation. It pushes interviewers toward gendered assumptions about who fits a role.
In practice, stereotypes lead some teams to assume men are stronger fits for technical roles and women for caregiving roles.
74% of women in technology jobs report experiencing gender discrimination, according to Pew Research Center.
To limit gender bias, anonymize early-stage screening, write job descriptions in gender-neutral language, and build balanced finalist pools so no candidate is a token. Standardized scoring keeps the focus on ability.
A study by Harvard Business Review showed if there’s one woman candidate up against three male candidates, she has 0% chance of being offered the job. There’s statistically ZERO chance she’ll be hired.
Name bias is judging a candidate based on their name alone, before any evidence of skill. Names can signal perceived ethnicity, gender, or age and trigger fast assumptions.
Names can also imply age. "Edith" and "Eugene" read as older than "Juniper" or "Jaxson," which can feed age-based assumptions.
The fix is straightforward. Remove names and other identifying details during initial screening so reviewers evaluate experience, not identity. Blind screening is one of the most direct ways to address name bias.
A landmark study published by the National Bureau of Economic Research found that resumes with stereotypically white-sounding names received 50% more callbacks than identical resumes with African American-sounding names.
Race and ethnicity bias is unfair treatment based on a candidate's racial or ethnic background. It can be explicit or unconscious, and it often hides inside "culture fit" judgments.
Research shows the problem is persistent. A study in the Proceedings of the National Academy of Sciences found no decline in discrimination against Black applicants in United States labor markets since 1989.
Race and ethnicity are protected characteristics under United States, Canadian, and European Union law, so this bias carries direct legal exposure. To address it, combine blind screening with structured interviews and standardized scorecards. Consistent criteria make it harder for racial assumptions to influence ratings.
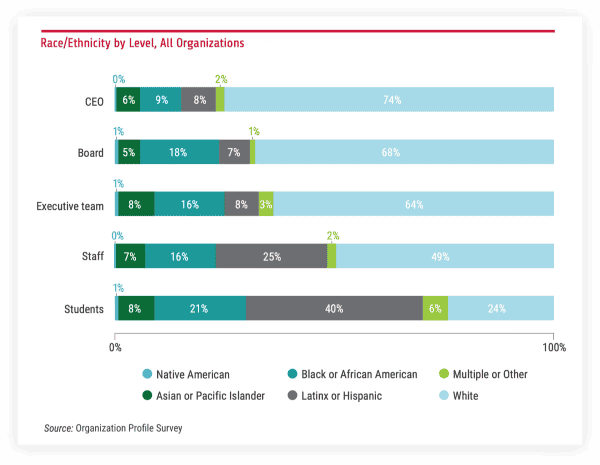
Age bias, also called ageism, is making unfair assumptions about candidates based on their actual or perceived age. It affects both older and younger applicants.
The Age Discrimination in Employment Act (ADEA) protects workers 40 and older in the United States. To limit age bias, remove graduation dates and ages from early screening and score candidates only on role competencies.
Research summarized by phys.org found older applicants faced 60% more age discrimination for entry roles.
Younger applicants were 70% less likely to win senior roles. Nearly two-thirds of workers aged 55 to 64 say age is a barrier to getting hired, per SHRM.
Appearance bias, sometimes called lookism, is the assumption that how a candidate looks predicts how they will perform. It extends to attractiveness, weight, height, and age-related appearance.
This is a form of the halo effect. People who match conventional beauty standards are often perceived as more competent, which can win them interviews they did not earn on merit. When asked how central employee appearance is to business success, 93% of employers called it critical or important, per the Journal of Industrial Relations. This "beauty premium" rewards looks over skill.
To counter appearance bias, lead with skills assessments and structured, competency-based questions. Pre-recorded interviews scored against a rubric keep evaluators focused on answers.
Classification bias is sorting candidates into groups and applying assumptions about that group to the individual. It is the engine behind many demographic biases, including those tied to race, age, religion, disability, and sexual orientation.
In hiring, it appears when an interviewer assumes a candidate from a given background will or will not have certain traits. The individual disappears behind the category.
The impact is unfair rejection of qualified people and reduced workforce diversity. To address it, define the specific competencies a role requires and score every candidate against those, not against group assumptions. Structured evaluation is the most reliable counter to stereotyping.
Affinity bias is the tendency to favor candidates who feel familiar or similar to us. It is rooted in a natural desire to connect, but it functions as implicit prejudice in hiring.
It shows up when an interviewer rates a candidate higher because they share a hometown, school, or mutual contact. Skills become secondary to similarity. This is closely tied to in-group favoritism, where people extend trust to those they see as part of their group.
The impact is a less diverse team and a "personality silo" where new hires mirror existing staff. To limit affinity bias, use multiple interviewers with varied backgrounds and require each to score independently before discussing candidates.
Similarity-attraction bias, also called the similar-to-me effect, is favoring candidates who share your traits, background, or interests. It overlaps with affinity bias but centers specifically on perceived likeness.
An interviewer might rate a candidate more highly for sharing their alma mater or communication style, regardless of job fit. The more familiar a person feels, the more capable they can seem.
This narrows diversity and rewards sameness over skill. Diverse interview panels are the strongest counter, since different evaluators share different traits with a candidate and balance one another out. Independent scoring before group discussion keeps individual likeness from steering the decision.
Conformity bias, often called groupthink, happens when interviewers abandon their own judgment to align with the group. It is common in panel interviews and debrief meetings.
For example, if four of five interviewers favor one candidate, the fifth may agree to fit in, even after privately preferring someone else. A useful perspective is lost.
The impact is false consensus that hides real disagreement. To counter it, collect every interviewer's scores independently and in writing before any group discussion. This preserves dissent and surfaces patterns the room might otherwise smooth over.

Confirmation bias is forming an early impression of a candidate and then seeking evidence that proves it right. It can be positive or negative, and it shapes the entire interview.
It appears in three ways. Selective search is asking leading questions to elicit answers that confirm your view. Selective interpretation is reading the same answer as strong or weak depending on your existing opinion. Selective recall is remembering details that support your impression and forgetting those that contradict it.
The impact is an interview that confirms a snap judgment instead of testing it. To limit confirmation bias, ask every candidate the same questions in the same order, and score each answer before moving to the next. Structured interviews and pre-recorded responses make it harder for a first impression to color everything that follows.
The halo and horns effects are snap judgments driven by a single attribute. The halo effect lets one positive trait inflate the whole evaluation, while the horns effect lets one negative trait sink it.
The halo effect appears when an interviewer fixates on a prestigious university and overlooks weaknesses. The horns effect appears when an unrelated negative, such as visible tattoos, drags down an otherwise strong candidate.
Both replace a full assessment with a single data point. To counter them, evaluate candidates against several defined competencies separately, so one trait cannot dominate the score. Scorecards force a more complete view.
Attribution bias, or the fundamental attribution error, is misjudging the cause of a candidate's behavior. Interviewers credit favored candidates' wins to talent and blame others' setbacks on character.
For example, a team might read one candidate's layoff as a personal failing but credit a preferred candidate's promotion to skill. The same evidence gets two readings. To address it, ask behavioral questions that probe context and actions, and score each answer against a rubric rather than against assumptions about why something happened.
Authority bias is giving outsized weight to the most senior person's opinion in the room. Decisions follow rank instead of evidence, and it often compounds conformity bias.
In a debrief, a junior interviewer with strong notes may defer to a leader's gut reaction. To counter it, collect written scores from every interviewer before the senior person speaks, and weight all evaluations equally against the agreed criteria.
Intuition bias is relying on a gut feeling about a candidate instead of evidence. "I just know they're a good fit" is the signal phrase.
Gut decisions feel confident but track poorly with actual job performance. They also tend to favor whoever is most familiar or likeable, which smuggles in affinity and halo effects. Overconfidence makes this worse: many evaluators believe they are less biased than their peers, a pattern known as the bias blind spot.
A study in the German Journal of Human Resource Management surveyed 234 HR professionals and found they rated colleagues as more biased than themselves. To counter intuition bias, anchor decisions to scored interviews and skills data, and treat gut reactions as hypotheses to test rather than conclusions.
The representative heuristic is judging candidates by how closely they match a mental image of the "ideal" hire. The closer the match to that prototype, the higher the rating.
This favors people who fit a preconceived profile and overlooks equally qualified candidates who do not. It is stereotyping framed as pattern recognition. To address it, define success by measurable competencies and validated skills assessments, not resemblance to past hires.
Contrast, anchoring, and order effects are evaluation biases driven by comparison, first information, and interview sequence. Each one lets something other than merit shape the score.
The contrast effect judges a candidate against the previous one, so an average applicant after a strong one looks weaker than they are. Anchoring bias over-relies on the first detail, such as a salary figure or opening answer, which then skews everything that follows. The recency and primacy effects distort memory by order, since evaluators best remember the first and last candidates while strong applicants in the middle fade.
To counter all three, score each candidate against a fixed rubric immediately after their interview, before the next begins. Reviewing pre-recorded responses gives every candidate equal, undistorted attention regardless of order.
AI bias, also called algorithmic bias, is unfair hiring outcomes produced by an automated tool. It happens when an AI system learns discriminatory patterns from the data it was trained on.
Most AI bias traces back to the training data. If a tool learns from past hiring decisions that favored one group, it reproduces that preference in resume screening or scoring. It can also pick up proxies for protected traits, such as a zip code that correlates with race.
Flawed inputs create bias too. The EEOC warns that analyzing speech patterns can disadvantage candidates with disabilities, and that facial analysis can score darker skin tones less accurately. Using AI does not change an employer's anti-discrimination obligations.
A well-known example is Amazon. In 2018, the company scrapped an internal recruiting tool after finding it penalized resumes that mentioned "women's," because it had learned from a decade of mostly male applicants.
The danger of AI bias is scale. It applies the same flawed judgment to thousands of candidates at once, wrapped in a false sense of objectivity. A related risk is automation bias, where people trust a score simply because a computer produced it.
To guard against AI bias, choose tools that score what candidates said rather than how they look or sound. Audit them regularly for disparate outcomes, and keep a human in the loop on every decision. VidCruiter's AI Interview Scoring follows this approach. AI can also support fairer hiring when deployed carefully, as covered in "Can AI Reduce Interview Bias?" below.
You reduce hiring bias by changing the process, not just the people. The most effective interventions standardize how candidates are evaluated so individual judgment has less room to drift. Bias reduction is a system design problem, and the tactics below are ordered roughly by strength of evidence.

Structured interviews are the single most evidence-backed way to address the impact of bias. Every candidate gets the same questions, in the same order, scored against the same criteria.
Decades of industrial and organizational (I/O) psychology research rank structured interviews among the most predictive and fairest selection methods available. They consistently outperform unstructured conversations, which leave wide room for bias and make discrimination hard to prove.
How they differ
Structured interviews
Unstructured interviews
Preparation
Questions planned and aligned in advance
Poorly planned; questions vary by interviewer
Questions
Identical for every candidate
Change based on the candidate
Focus
Behavioral, tied to role competencies
Conversational, tied to rapport
Scoring
Independent ratings on a shared rubric
Holistic impression
Bias risk
Lower and easier to audit
Higher and hard to detect
VidCruiter's structured interviews apply this method over video, giving teams a consistent process and a reviewable record.
A standardized scorecard defines how candidates are rated before interviews begin. It replaces vague impressions with specific, comparable scores.
Rank the competencies a role requires, agree on what each rating level means, and have every interviewer use the same matrix. Scoring each answer separately limits the halo, horns, and contrast effects. See VidCruiter's guide to the interview scorecard for implementation detail.
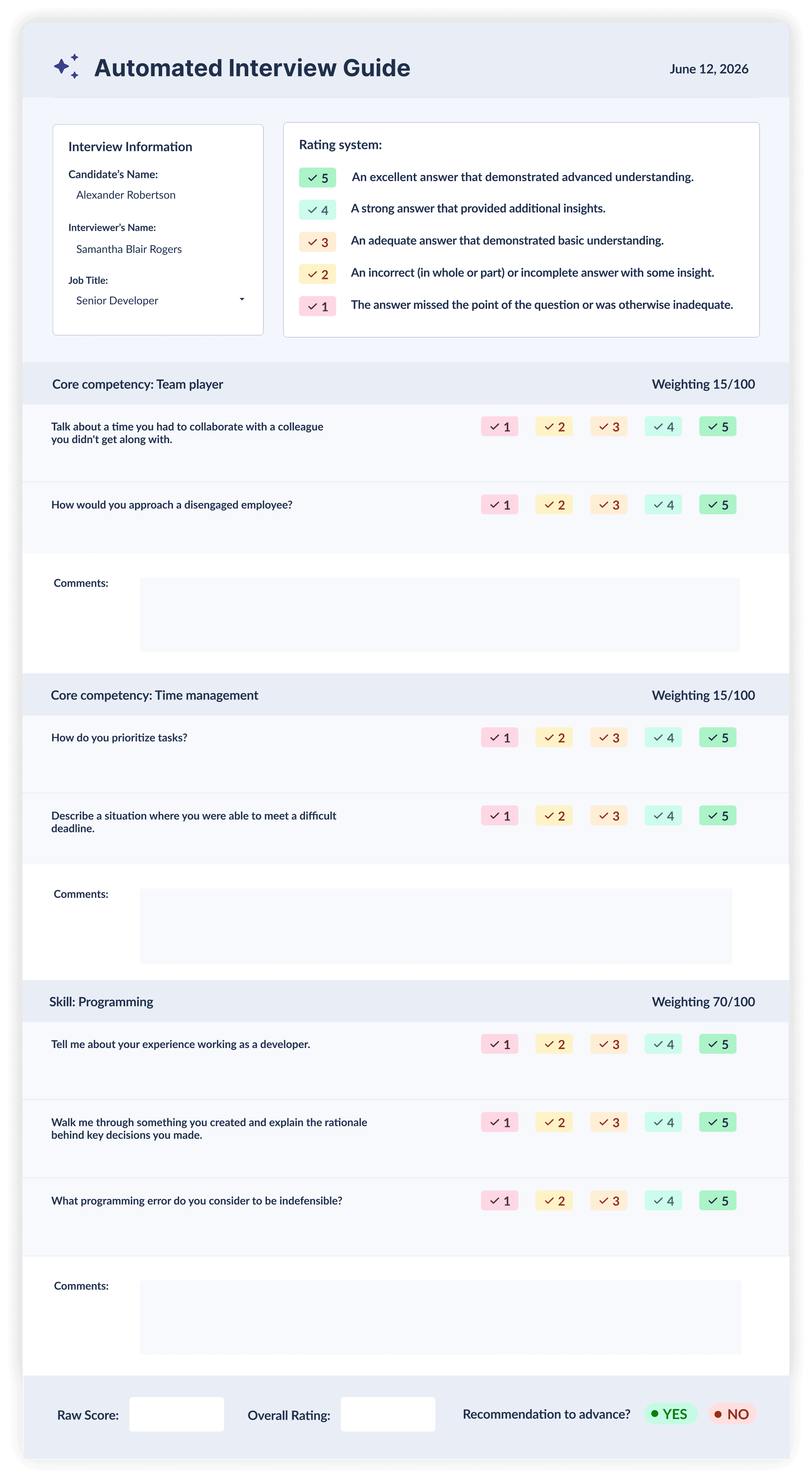
Blind screening removes identifying details from applications during early review. Names, photos, ages, and graduation dates removed before reviewers see the resume.
This directly targets name bias, race and ethnicity bias, gender bias, and age bias at the stage where they do the most damage. Reviewers evaluate experience and skills, not identity.
Diverse panels counter affinity, similarity-attraction, and conformity bias by bringing different perspectives to the table. Different evaluators notice different things and balance one another's blind spots.
Where possible, include interviewers from underrepresented groups, and have each panelist score independently before the group discusses. This exposes individual rater patterns over time.
Pre-recorded interviews give every candidate the same questions and conditions, then let evaluators score on their own schedule. This consistency limits recency, primacy, and contrast effects.
Recorded responses also create a reviewable record, so teams can audit decisions and spot recurring bias. VidCruiter's pre-recorded video interviews also widen access for candidates in different time zones and circumstances.

Skills tests measure whether a candidate can do the job, using objective criteria set in advance. They shift evaluation from impressions to demonstrated ability.
Run them early, before interviews, to set an objective baseline and screen on merit. VidCruiter's skills testing ties assessments directly to day-to-day role tasks.
Bias awareness training helps interviewers recognize their own patterns, but the evidence on it is mixed. Awareness alone rarely changes behavior for long.
Research by HBR found the effects of one-off unconscious bias training fade quickly. Training helps only as part of a wider system change, not as a standalone fix.

AI can help limit interview bias, but only as a support to human judgment, not a replacement for it. Used well, it makes fair processes faster. Used carelessly, it amplifies the problems described in the AI bias section above.
AI works best on the operational tasks around a structured interview. It can coordinate scheduling, draft job-related and legal interview questions, take notes, produce competency-based summaries, and flag interviews for compliance review. This frees interviewers to focus on the decision itself.
Human oversight is the deciding factor. Research from the University of Washington found that reviewers tend to follow AI recommendations even when those recommendations are clearly biased. Around 59% of United States adults surveyed in 2025 believe AI is increasing workplace bias rather than reducing it, according to SHL. A real person should review every AI output before any shortlist, interview, or offer decision.
When evaluating vendors, favor those that audit their models, explain the maturity of each feature honestly, and require human review. VidCruiter takes this position directly: it does not use AI to autonomously assess candidates or analyze voice and facial expressions. See the VidCruiter AI framework for how to document responsible AI use.
Adverse impact is when a neutral-looking hiring practice produces a worse outcome for a protected group. It can create legal liability even when no one intended to discriminate, because regulators measure outcomes, not intent.
The standard test is the 4/5ths rule, also called the 80% rule. Under the United States Uniform Guidelines on Employee Selection Procedures, if a group's selection rate is less than 80% of the rate for the highest-selected group, that gap is treated as evidence of adverse impact. For example, if 50% of one group passes a screen but only 30% of another does, the second group's rate is 60% of the first, below the threshold.
Protected characteristics under United States law include race, color, religion, sex, national origin, age, and disability, enforced by the Equal Employment Opportunity Commission (EEOC). Similar protections exist in Canada, the United Kingdom, and the European Union.
Regulation of automated hiring tools is expanding quickly. Recent developments include:
To audit for adverse impact, calculate selection rates by group at each hiring stage, apply the 4/5ths rule, and document the process. Structured, consistent evaluation makes both the audit and the defense far easier.
Candidates who suspect bias in a hiring process do have options, though the burden should never fall on them alone. Recognizing the signs is the first step.
Watch for interviews that feel inconsistent, questions unrelated to the job, or remarks about age, family plans, or background. These can signal an unstructured, bias-prone process.
You can ask how candidates are evaluated and whether scoring is standardized. If you experience discrimination based on a protected characteristic, you can document it and contact the relevant authority, such as the EEOC in the United States or a provincial human rights commission in Canada. For job seekers, prioritizing employers with structured, transparent processes is a practical filter.
Unconscious biases such as affinity bias and confirmation bias are the most common in hiring. They operate without the interviewer's awareness, which makes them more widespread and harder to correct than explicit bias. Structured evaluation is the most reliable way to limit them.
Conscious bias is an explicit preference a person recognizes and may openly express. Unconscious bias operates below awareness and surfaces as gut feelings or snap judgments based on stereotypes. Unconscious bias is more common in hiring and harder to identify and address.
AI bias, or algorithmic bias, is when an automated hiring tool produces unfair outcomes for certain groups. It usually comes from biased training data or flawed inputs like speech or facial analysis. Employers stay legally responsible for discriminatory results, so regular audits and human review are essential.
AI can do either, depending on design and oversight. A tool trained on biased data can amplify discrimination at scale, while a well-audited tool with a human in the loop can support more consistent evaluation. The safeguards are regular bias audits, scoring the substance of answers, and human review of every decision.
Yes. Structured interviews are among the most evidence-backed methods for limiting bias, according to decades of industrial and organizational psychology research. They give every candidate the same questions and scoring criteria, which makes evaluation more consistent and easier to audit than unstructured interviews.
Adverse impact is when a neutral hiring practice disadvantages a protected group, regardless of intent. It is commonly measured with the 4/5ths rule: if one group's selection rate is below 80% of the highest group's rate, that gap signals adverse impact. Employers should audit selection rates at each hiring stage.
The evidence is mixed. Research shows that one-off unconscious bias training raises awareness but rarely changes behavior for long. Training helps only when paired with process changes such as structured interviews and standardized scoring. On its own, it is not a reliable fix.
Pre-recorded video interviews can limit bias by giving every candidate the same questions and conditions, scored against a shared rubric. They reduce recency, primacy, and contrast effects and create a reviewable record for auditing decisions. Poorly designed AI analysis of video can introduce new risk, so human review matters.
The 4/5ths rule, or 80% rule, is a test for adverse impact from the United States Uniform Guidelines on Employee Selection Procedures. If a protected group's selection rate is less than 80% of the highest-selected group's rate, regulators treat that as evidence of adverse impact requiring review.
Biases tied to protected characteristics are illegal under United States law, including race, color, religion, sex, national origin, age (40 and older), and disability. Acting on these in hiring violates laws enforced by the EEOC. Many other biases are not illegal but still harm hiring quality and fairness.
No. Bias cannot be fully eliminated because it is rooted in normal human cognition. The realistic goal is to design a process that limits its influence, through structured interviews, standardized scoring, blind screening, and regular auditing. Consistent systems substantially address the impact of bias on outcomes.
Modernize your hiring process with expert insights and advice.